A webbel kapcsolatos hírek egyik fő „hívószava” a HTML5 lett az elmúlt bő fél évben (és persze az „elfogytak az IP-címek” című rémtörténet). Ezen cikkek jelentős részében a HTML5 tulajdonképpen egy szép nagy „doboz” címkéje volt, és ebbe a dobozba nagyon sok minden más is belefért a szerzők és a szerkesztők szerint – leginkább a kaszkád stíluslapok újdonságai, és ezek közül is jellemző módon az egyelőre kizárólag a webkites böngészők által támogatott transzformációk. De az az igazság, hogy valóban nem is egyszerű pontosan megfogalmazni, hogy mi az a HTML5.

2011. január 18-án mutatta be a W3C a HTML5 "hivatalos logóját"
Ugyanis túl azon, hogy természetesen a web fő jelölőnyelvének, pontosabban jelölőnyelveinek, a HTML 4.01-nek és az XHTML 1.1-nek új változatáról beszélünk, még hozzá kell értenünk több mint egy tucat alkalmazásprogramozási felületet (Application Programming Interface, API) is. Ezek implementációi gondoskodnak majd a böngészőkben például az oldalak – már-már álomszerűnek hangzó – egységes megjelenítéséről, a webes űrlapok kezeléséről, a videók és hangok lejátszásáról, a vektorgrafikus ábrák kirajzolásáról, esetleg mozgatásáról, földrajzi adatok alkalmazásáról stb.
Rövid HTML-történelem
Ahhoz, hogy egy kicsit jobban megértsünk, miért is ilyen kusza néhány dolog a HTML5 körül, nem árt kicsit tisztában lennünk magának a HTML-nek a történelmével. Az első HTML-specifikációt Sir Timothy John Berners-Lee, vagy ahogy inkább ismerik, Tim Berners-Lee készítette el 1991 októberében, ahogyan az ő nevéhez fűződik az első webszerver és az első böngésző is. Ez az első HTML-változat – leszámítva a hiperlinket – igen jelentős mértékben alapozott az SGMLguidre, a CERN-nek, Berners-Lee akkori munkahelyének saját SGML-alapú dokumentumformátumára. Ez a leírás 20 címkét tartalmazott, amelyekből 15 megtalálható a HTML 4.01-ben is: a "title", az "a", a "p", a "h1...h6", az "address", a "dl", a "dt", a "dd", az "ul" és a "li".
Az ötlet sokaknak megtetszett, ám komoly problémát okozott, hogy miután nem volt olyan, hogy „HTML-szabvány”, a böngészők (például a Cello, Arena, Lynx, Mosaic) gyártói az alap 20 címkét elkezdték a saját ötleteik alapján bővíteni, amiből igen jelentős káosz lett. Hogy megpróbáljanak úrrá lenni ezen, Berners-Lee és Dan Connolly összeszedték a különböző böngészőgyártók fejlesztéseit, és ezeket is figyelembe véve elkészítették az első HTML DTD-t (Document Type Definition), ami alapját képezte a HTML 2-nek.
1994 októberében Tim Berners-Lee vezetésével megalakult a World Wide Web Consortuium (W3C), akiknek tagjai, megunva az IETF (Internet Engineering Task Force – az interneten használatos szabványok kidolgozásáért és felügyeletéért felelős szervezet) HTML-munkacsoportjának nehézkességét, és egy kisebbfajta „forradalom” keretében átvették az irányítást a HTML fejlesztése felett.
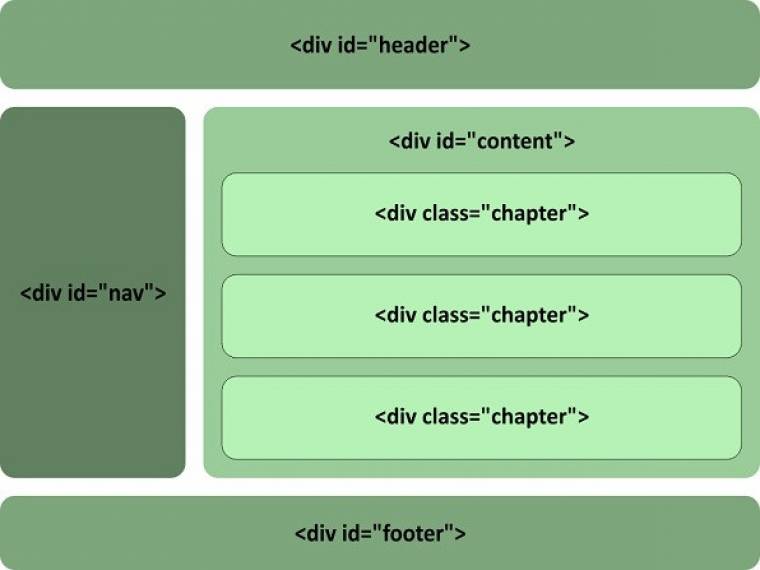
Egy átlagos oldal HTML4-XHTML alapokon...
Ezt követően kicsit felgyorsultak az események: 1995 novemberében hivatalossá vált – IETF-szabványként – a HTML 2.0 (ami nem ugyanaz, mint a HTML 2); másfél évvel később, 1997 januárjában hivatalos W3C-ajánlásként jelent meg a HTML 3.2 (a 3.0 ún. draft, azaz csak tervezet volt, a 3.1 pedig valahol eltűnt); majd még decemberben megérkezett, rögtön három variációban (strict, transitional és frameset) a HTML 4.0. A lendület ezen a ponton kissé megtört, pontosabban a W3C úgy gondolta, hogy a HTML-nek az XML irányába kell elindulnia. Azért 1999 karácsonyára még kiadták a HTML 4.01-et, amelynek strict változata ISO-szabvány lett (ISO/IEC 15445:2000).
Gyakorlatilag a HTML 4.01-val együtt, 2000. január végén jelent meg az „új HTML”, az egyre népszerűbb XML alapjaira építkező XHTML 1.0 ajánlása, amit bő egy évvel követett a modulokra bontott, elvben sokkal szigorúbb 1.1-es változat. Azért csak elvben, mert az igazi szigorúságot, a szintaktikailag helytelen oldalak helyett csak valamilyen hibaüzenet megjelenítését a Microsoft, mint az akkori piacvezető böngészőgyártó – valahol érthető okokból – megtorpedózta.
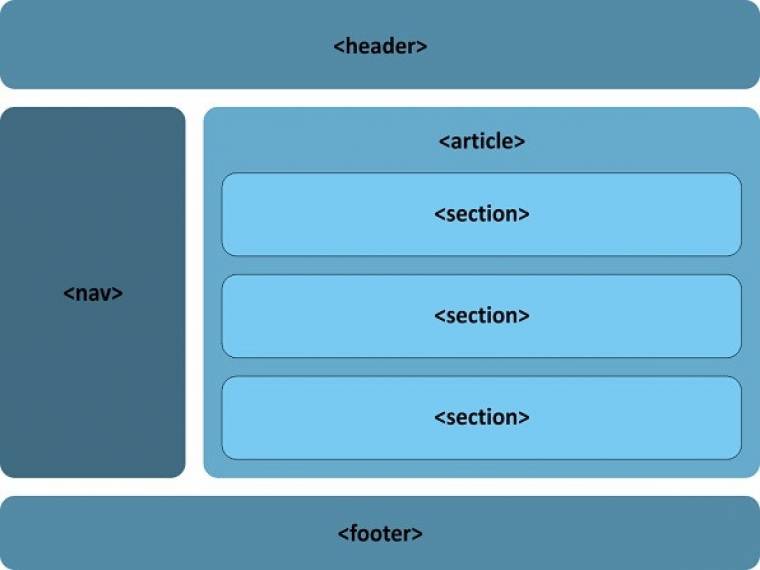
...és követve a HTML5-ajánlásokat
A W3C ezt követően teljes erővel kezdett el dolgozni az XHTML 2.0-n, egy teljesen új, természetesen szintén XML-alapú leíró nyelven, amely nem kompatibilis a korábbiakkal, a „hagyományos” HTML fejlesztését pedig teljesen leállították, ám igazából nem tudni pontosan, miért, megtört a korábbi nagy lendület, és néhány évvel később némiképp ironikus módon a történelem megismételte önmagát. Jött egy lelkes fiatalember, nevezetesen a svájci Ian Hickson, aki akkoriban az Opera kutatómérnökeként dolgozott, és miután egy 2004-es W3C munkaülésen egy javaslatát visszautasították, az Apple és a Mozilla Alapítvány embereivel közösen 2004 júniusában megalapította a Web Hypertext Application Technology Working Groupot, azaz a WHATWG-t. A munkacsoport fő célkitűzése a HTML-nyelv és a webes programok létrehozásához szükséges alkalmazásprogramozási felületek fejlesztése volt.
A WHATWG, és főként Hickson munkamódszere drasztikusan eltért az abszolút demokratikus elveket valló W3C-étől, de mondhatjuk úgy is, hogy Tim Berners-Lee-étől. Jelentős mértékben leegyszerűsítve míg a dolgokat a W3C-nél minden egyes lépést egy aprólékos vizsgálat előz meg, a döntéseknek pedig teljes konszenzuson kell alapulniuk, addig a WHTAWG-nél az egyes megbeszéléseket, esetleg vitákat követően Hickson dönti el, hogy merre tovább – ugyanakkor a fő böngészőgyártóknak vétójoguk van, és ha valamire azt mondják, hogy nem csinálják meg, akkor azzal a nyelvi elemmel vagy programozói megoldással nem foglalkoznak tovább.
A végeredményt valószínűleg elsősorban nem a két „munkamódszer”, hanem az út elején kijelölt irányok döntötték el. Több mint két évvel később, 2006 októberében ugyanis a W3C-nél is felismerték, hogy a színtiszta XML-alapú web létrehozása lehetetlen, ám még további három évre volt szükség, hogy a W3C bejelentse, hogy az XHTML 2.0 „halott”. Időközben a W3C is létrehozta saját új HTML-munkacsoportját, amely 2007 májusa óta a WHATWG „munkájára épít”; azóta mondhatni közösen, bár sokszor furcsán párhuzamosan dolgoznak a HTML5-ön.
E párhuzamosság egyik látványos mintapéldája volt, hogy 2011. január 18-án a W3C bemutatta a technológia hivatalos „szuperhősös” logóját, ahogy ők fogalmaztak, hogy „ezzel is ösztönözzék a korai bevezetőket a HTML5 használatára” – majd egy nappal később, 2011. január 19-én Ian Hickson a WHATWG blogjában bejelentette, hogy mostantól kezdve nem lesz HTML-verziószám, hanem egy „élő dokumentum” lesz, amelyet folyamatosan fognak fejleszteni.
A jelenre építkezve – laza pórázon
A WHATWG homlokegyenesen más irányt választott, mint a W3C az XHTML 2.0 alapkövének letételekor, vagyis fontos szempont volt a kompatibilitás a működő weboldalakkal, de ugyanakkor természetesen szükség volt „robusztus újításokra” is, hiszen egy több mint tízéves szabvány új verzióját kell elkészíteni. Abban is más volt a WHATWG hozzáállása, hogy nem az elmélet, hanem elsősorban a felhasználók és a webfejlesztők oldaláról közelítették meg a különböző kérdéseket, és ráadásul mindezt a tagok, azaz a böngészőgyártók szemszögéből vizsgálva. A kényes egyensúly – vagyis a kompatibilitás kontra innováció – megtartása miatt „akkurátus webfejlesztői szemmel” néhány igen érdekes döntés is született.
Így néz ki nyitóoldalunk "HTML5-ösítve"
Például nagyon-nagyon „laza pórázra engedték” a webfejlesztőket. Azt még kimondottan pozitívan is nézhetjük, hogy jelentősen egyszerűbbé tettek olyan elemeket, mint a DOCTYPE, a különböző metainformációk, vagy a stíluslapok és JavaScript állományok csatolása. Így például, amit eddig úgy kellett írnunk, hogy:

Vagy úgy, hogy:

Abból ezentúl mindössze ennyi maradt:

Hasonlóképpen az oldalunk karakterkódolásának megadása eddig így nézett ki:

Ezentúl pedig így fog:
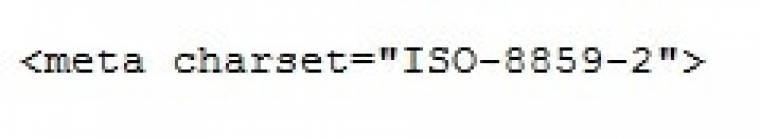
Ha pedig a stíluslapjaink formátuma mindig „text/css”, akkor azt miért kell megadnunk? Ne kelljen, így a

helyett a jövőben használhatjuk a
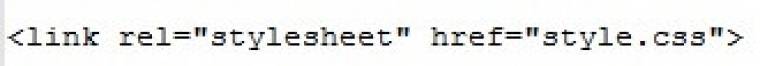
formát is.
Ahogyan már igen ritka, hogy egy oldalon a kliensoldali program nem JavaScript, akkor minek ezt mindig kiírni? A

helyett elég lesz az is, hogy

Azonban az már erősen kérdéses, hogy valóban hasznos újdonság, hogy a webfejlesztők maguk dönthetik el, hogy kis- vagy nagybetűvel írják-e a címkék vagy az attribútumok neveit, előbbieket bezárják-e vagy sem, utóbbiak értékét pedig írhatják idézőjelekkel, de azok nélkül is. Természetesen attól, hogy valamit lehet rosszul csinálni, az nem jelenti azt, hogy kell is, de sokan – teljesen jogosan – félnek ettől a túl nagy szabadságtól.
Természetesen eddig is lehetett hibás kódokat írni – találkozhatunk is ilyenekkel bőven –, amelyeket a böngészők a maguk módján próbáltak meg kijavítani, ám ezentúl ezt a szakembereknek nem a saját fejük után menve kell majd megtenniük, hanem ezek mikéntjét pontosan szabályozza, vagy szabályozni fogja az új HTML-specifikáció, amiben állítólag szerepelni fog minden lehetséges hibafajta. Elsőre bármilyen ijesztőnek is tűnik, az alábbi kód teljesen szabályosnak mondható:

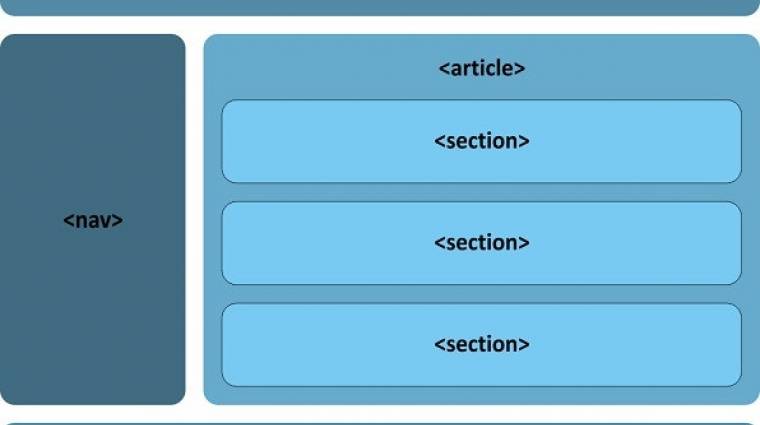
Új strukturális elemek
Bár a „bulvár” számára a „video” és az „audio” a fő HTML5-elemek, igazából az egyik legfontosabb hozadéka az új nyelvnek a szemantikus web alapelemeinek lerakása. Még bőven a HTML5 „első stádiumában” a Google és az Opera egymástól függetlenül elvégezte több millió, sőt a Google esetében több mint egy milliárd weboldal elemzését, és megvizsgálták, hogy a webfejlesztők milyen azonosító- és osztályneveket használnak az oldalak kódjaiban. Nem meglepő módon, néhány generált oldalakra jellemző semmitmondó név mellett, olyan vissza-visszatérő nevekkel találkoztak, amelyek az egyes elemek funkciójára utaltak: header, footer, menu, nav, content, sidebar stb.
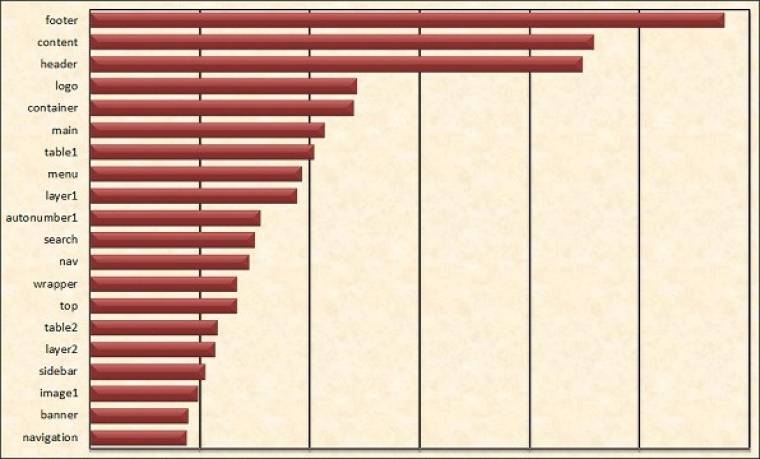
Több mint 2 millió oldalon a leggyakrabban előforduló osztálynevek - az Opera gyűjtése alapján
Ezek nyomán születtek meg azok az új címkék, amelyek a jövőben segít(het)nek abban, hogy oldalaink még jobban strukturáltak, a kódok még áttekinthetőbbek legyenek. Hiszen most már nem lehet „ahány ház, annyi szokás” elven elnevezni az oldalak fej- és lábléceit (header és footer), az oldalak közötti és az oldalakon belüli hivatkozások listáit (nav), az oldalon belüli, önálló tartalommal bíró cikkeket, fejezeteket, blog bejegyzéseket stb. (article és section), az ezekhez a tartalmakhoz kapcsolódó, de mégis azokból valamilyen módon kiemelendő részeket (aside). Emellett most már egységesen jelölhetjük a dátumokat és időpontokat (time), a valamilyen módon kiemelésre szánt részeket (mark) vagy a különböző (fel)mérési eredményeket (meter) is.
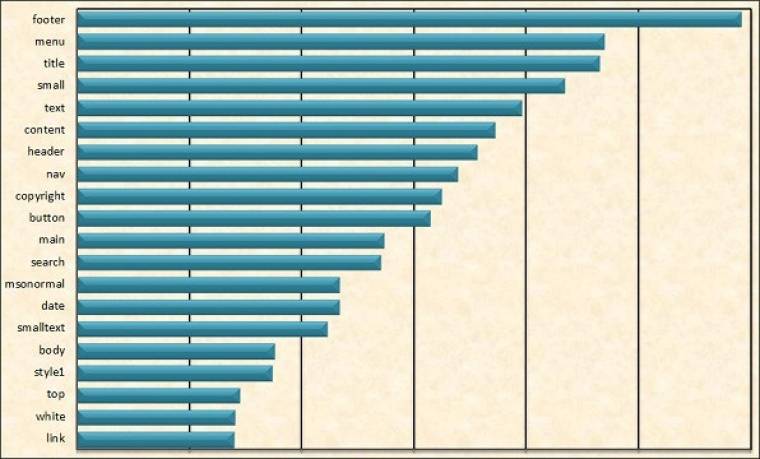
Egymilliárd oldalon a Google ezekkel az azonosítókkal találkozott a legtöbbször
Úgy tűnik tehát, hogy a HTML5 nagyon hasznos dolog lesz – igazából már az –, de még nem tudunk, nem tudhatunk tökéletes HTML5-oldalakat készíteni. A webfejlesztőknek folyamatosan figyelniük kell a frissülő ajánlásokat, az új böngészőket és a saját kódjukat, hogy valódi haszonélvezői lehessenek az új technológiának.
A cikkhez kapcsolódó mintaoldal innen tölthető le.
