A papíralapú dokumentumok nyomtatása szinte mindennapos rutin, de néha szükség van arra, hogy megfordítsuk a folyamatot, digitalizálva az egyszer már kinyomtatott szöveget. Ekkor csak egy megoldás van: optikai karakterfelismerő (OCR, azaz Optical Character Recognition) alkalmazást kell hadba küldenünk, amely a szkenner által beolvasott képen fel tudja ismerni a karaktereket: az ívük alapján meghatározza, hogy pontosan milyen betűről van szó. Szerencsére ez a munka meglehetősen jól mérhető – vagy eltalálja a szoftver a karaktert, vagy nem. Ezen ok miatt szinte adja magát egy összehasonlító teszt.

Szempontjaink
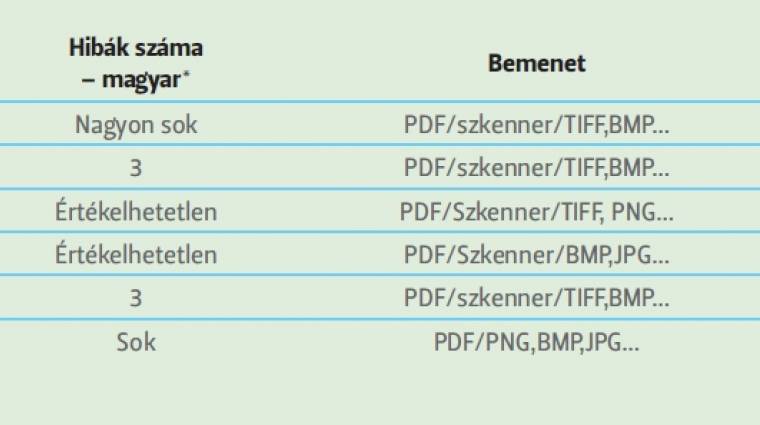
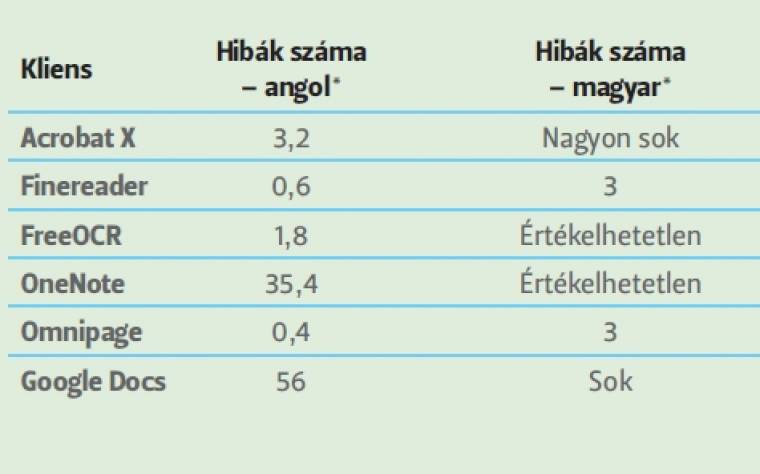
Az alapötletünk egyszerű: az a szoftver a legjobb, amelynél a legkevesebb felhasználói beavatkozás mellett sikerül a legjobban digitalizálni a kiindulási dokumentumot. E tekintetben fontos, hogy a program a lehető legpontosabban ismerje fel a karaktereket, kezelje azok formátumait, illetve az elrendezésre is tekintettel legyen. Kétszer 10 oldalt olvastunk be optimális 300 dpi felbontásban a pár oldallal előrébb ismertetett Canon DR-M160 szkennerrel minden esetben egyszer egy köteg nyomtatott angol szöveget, másszor ugyanennyi magyar nyelvűt.
Ezek után átlagoltuk a kapott hibaszámokat, így jöttek ki a lenti eredmények. Persze előfordult, hogy a szoftver minősíthetetlen eredményt adott vissza, különböző okok miatt; ekkor ezt nem számszerűsítettük, hiszen túl magas összeg lett volna, és lehet, hogy hamarabb be lehet ezen esetekben gépelni az adott szöveget.
Fontos azt is hangsúlyoznunk, hogy nyomtatott oldalakról beszélünk. Habár a technológia elméletileg az írt karaktereket is fel tudná ismerni, azt a tárgyalt alkalmazásokkal nem tudtuk elérni, pedig az éllovasokkal is megpróbáltuk a legszebb gyöngybetűinket a legnagyobb felbontás mellett felismertetni. Sikertelenül. Ezenfelül az eredményeknél tekintettel voltunk a szoftverek funkcióinak a számosságára, a felhasználói felületre, valamint természetesen azok ára sem volt mellékes tényező.
Akiket nem mértünk
Sajnos terjedelmi korlátok miatt nem tudunk bemutatni minden OCR-megoldást, így nem került be a cikkünkbe a Readiris, a TypeReader, az ingyenes Tesseract, a gImageReader és a Puma.net, valamint a webes megoldások közül az OnlineOCR.net, az OCR Terminal vagy az OCRonline.com sem. Így azt javasoljuk, hogy aki teheti, tegyen egy próbát ezen alkalmazásokkal is, hátha kincset talál – ám azt gyanítjuk, hogy a legjobb szoftver a mi összeállításunkból sem maradhatott ki.
Adobe Acrobat X Pro 10.1
A felhasználók egy jelentős csoportja nyomtatott dokumentumok szkennelésével hoz létre PDF fájlokat, így egy optikai karakterfelismerő modul is helyett kapott az Acrobat X Pro programban. Utóbbi segítségével a digitalizált fájlok között egyszerűen lehet keresni, illetve a szöveg másolhatósága is biztosított, azaz a felhasználóknak nem kell beruházniuk egy külön OCR-alkalmazásra, mivel az Acrobat X azt már alapból biztosítja. Eddig tartott a marketingszöveg, most nézzük, hogy mi a valóság: a tapasztalatunk alapján nem feltétlenül érdemes a program e képességében megbíznunk. Igaz ugyan, hogy angol nyomtatott dokumentumok esetén jól működik, de ha már magyar nyelvű oldalról van szó, akkor a Finereader és az Omnipage sok idegeskedéstől óvhat meg minket.
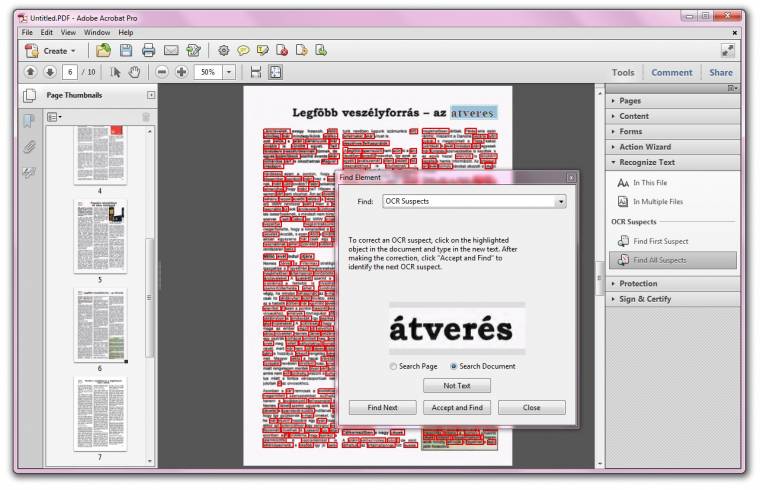
Az Adobe megoldása finoman szólva sincs jóban az ékezetes betűkkel és úgy egyáltalán a nyelvünkkel, pedig magyar szótárral már korábban felszerelték. Angol szövegek esetén is van egy idegesítő tulajdonsága, mivel mindenáron tartani akarja az oldal elrendezését, ezért sokszor felesleges szóközökkel szórja tele a szöveget, amit nem kis munka rendbetenni. Táblázatunkban ezért egy kissé kegyesek is voltunk a programmal, mivel ha e tényezőt nézzük, akkor szintén értékelhetetlen a produktuma. Persze az elrendezés szentségének van jó oldala is, hiszen így egy többhasábos digitalizált cikk sem esett szét a karakterfelismerés után, ami a többi alkalmazásnál jellemzően megtörtént. Mindemellett egy kicsit nehézkes a kezelése, hiszen azok után, hogy beolvastatjuk a dokumentumokat (Create, utána pedig PDF from Scanner) az eszközök menüben (Tools, majd Recognize Text) meglehetősen sok kattintgatással tisztázhatjuk a félreértéseket. Sokkal egyszerűbb, ha azonnal kimentjük a felismert szöveget Word dokumentumként; sok pepecseléstől óvhatjuk meg így magunkat. Összességében persze nem hibázik nagyot, aki OCR-munkához az Adobe megoldását használja, pláne ha inkább egy professzionális PDF-szerkesztőre, mint egy karakterfelismerőre van szüksége.
Fejlesztő: Adobe Systems Inc.
Ár: 207 ezer Ft
Web: adobe.com/hu
Kompatibilitás: Windows és Mac OS X
Előny: az OCR mellé egy professzionális PDF-készítő is jár
Hátrány: csak ezért drága, magyar nyelvnél küszködik
Teljesítmény: 3
Kezelhetőség: 4
Ár/érték: 3,5
FreeOCR 3
A fizetős szoftverek mellett természetesen az OCR-szférában is helyük van az ingyenes szoftvereknek. E téren a cikkünkben tárgyalt FreeOCR mellett meglehetősen népszerű a Cuneiform OpenOCR, a FreeOCR, a Puma.NET vagy a SimpleOCR. Mi most a Ralph Richardson által fejlesztett alkalmazást mutatjuk be egy kicsit részletesebben, amely a Google által szponzorált Tesseract OCR-motorra épül, azaz a felhasználói felület alatt egy komoly tudású karakterfelismerő dolgozik. A nyílt forráskódjának köszönhetően számos nyelv érhető el a programhoz, köztük például a magyar is, amely tapasztalatunk szerint sajnos nem akar együttműködni az ingyenes alkalmazással. Vélhetően a gond ott van, hogy a Tesseract és a nyelvi csomag már a hármas verziónál tart, míg a FreeOCR egy kissé lemaradt, enélkül pedig nehéz jó véleménnyel lenni a karakterfelismerőről, hiszen angolul még csak-csak használható, de magyar nyelvre átállítva megáll a tudománya. Pedig lenne keresnivalója, mivel a támogatott nyelveken jól teljesít, ráadásul a Google Dokumentumoktól és a OneNote-tól eltérően párhuzamos ablakokkal segíti az esetleges hibák kijavítását is.
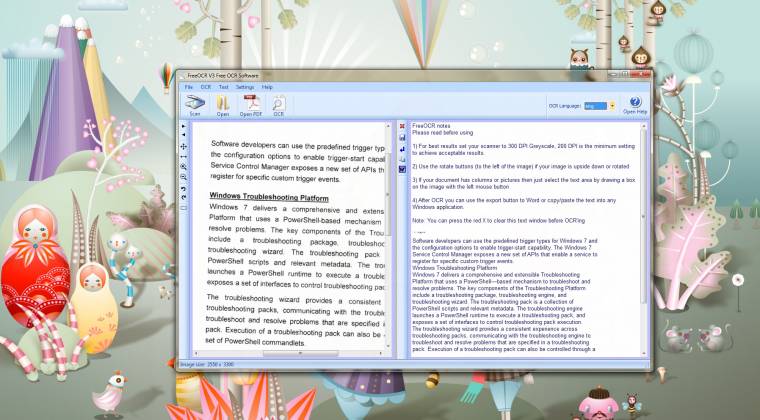
Egyedi, hogy a programban egyszerre csak egy beszkennelt oldallal dolgozhatunk, ellenben a szövegsáv minden egyes OCR-parancs után bővül, így nem kell az oldalakat egyenként lementegetni. Mivel pedig egyszerű szöveget állít elő, ezért a formátumokat és az oldal elrendezését sem menthetjük át, ráadásul a motorja mindent próbál lefordítani, nem nézi, hogy mivel van dolga, így ha egy kép karaktereket tartalmaz, akkor azt is értelmezi a program és belefolyatja a szövegbe; ezt később nehéz kiszúrni, mivel a kérdéses részek sehogyan sem különülnek el, pedig jó lenne, mert így nehéz átlátni a szöveget, amelynek még a betűmérete sem állítható. Szintén hiányosság, hogy a programon belül nincs vissza gomb, így elég egy rossz mozdulat, és kedvezőtlen forgatókönyv esetén kezdhetjük újra elölről a munkánkat.
Erős mezőnybe került a FreeOCR, amely jól jöhet akkor, ha egyszeri alkalommal kell valamit digitalizálnunk.
Fejlesztő: Ralph Richardson
Ár: ingyenes
Web: paperfile.net
Kompatibilitás: Windows
Előny: ingyenes, jó OCR-modul
Hátrány: fapados, magyar nyelvnél nem működik
Teljesítmény: 2
Kezelhetőség: 3
Ár/érték: 4
ABBYY FineReader 11.0
Az optikai karakterfelismerő program pár hónappal ezelőtt megjelent új verziója (a teszt 2011. szeptemberi számunkban olvasható) számos újdonsággal gazdagodott. Olyan ínyencségek kerültek bele, mint az ODF, az FB2 és az EPUB formátumok támogatása (immár a Kindle.com kiszolgálón keresztül is lehet frissíteni az e-olvasókat), valamint a lefotózott névjegykártyák vCard formátumba való kimentése. Emellett gyorsabb és pontosabb is lett a Finereader feldolgozó motorja, így jelenleg az egyik legjobb, ha nem a legjobb OCR-programról beszélhetünk személyében. Gazdag funkcionalitása már az első indítás után tetten érhető, hiszen elvégezhető feladatok széles skáláját ajánlja fel, ráadásul egy dokumentum beolvasása után is számos lehetőségünk van: előállíthatunk egy pontos másolatot, egy szerkeszthető variánst, illetve akár elektronikus könyvolvasóra is optimalizálhatjuk a szöveget.
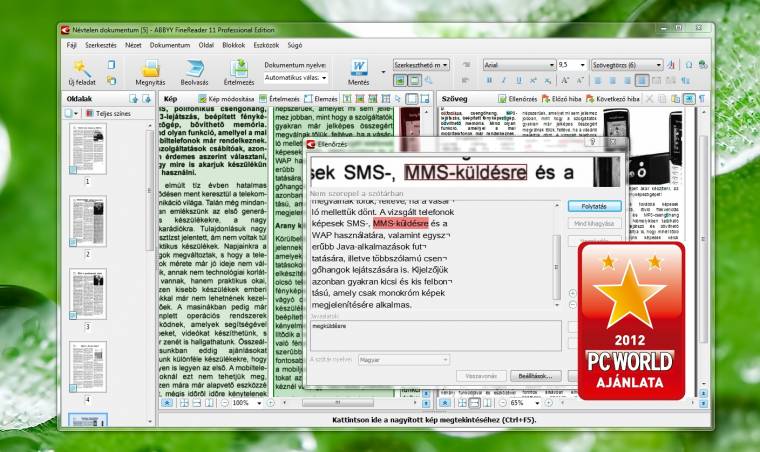
A Finereader 11 már a telepítés után rendelkezik a magyar nyelv támogatásával, amelyet automatikusan érvényesít a program, sőt az értelmezés után a beépített szótárával finomítja a szöveget. Összességében így csak nagyon kevésszer téved az alkalmazás, ami miatt a felhasználóknak a legtöbb esetben nincs sok tennivalójuk az analizált dokumentumokkal. Ráadásul az elrendezést és a formázásokat is jól kezeli a program, majd' minden esetben megtartja azokat, az adott térhez igazítva a szöveget. Ha pedig ez még nem lenne elég, akkor a nyelvszerkesztő, a stílusszerkesztő és a tanuló üzemmód is rendelkezésünkre áll. Egyébként tapasztalatunk alapján főként az „í”, az „ó” és az „ő” karaktereknél bizonytalankodik az OCR-modul, miközben az esetek legnagyobb részében ezzel együtt is jól használja azokat. A Finereader nagyon pontosan felismeri azt is, hogy mikor van dolga képpel, szöveggel és ábrával, így a felesleges elemeket nem is próbálja meg értelmezni, azokkal amúgy is csak szétesne a céldokumentum. Összességében egy gyors és hatékony optikai karakterfelismerőről beszélhetünk, amely megérdemli a PC World Ajánlata díjat, bár a döntés nem volt teljesen egyértelmű.
Fejlesztő: ABBYY
Ár: 40 000 Ft (Professional)
Web: ocrszoftver.hu
Kompatibilitás: Windows és Mac OS X
Előny: megbízható, gazdag funkcionalitás
Hátrány: nem találtunk
Teljesítmény: 4,5
Kezelhetőség: 5
Ár/érték: 4,5
Google Dokumentumok
A világhálón számos olyan ingyenes webszolgáltatás érhető el, amelyekkel kliensoldali program telepítése nélkül is digitalizálhatjuk a beolvasott szövegeinket. Ilyen például a Free-online-ocr.com, az i2OCR, az OCRonline.com, az onlineocr.net és a Google Dokumentumok is. Mi tesztelésre az utóbbit választottuk ki, már csak azért is, mivel a Gmail-fiókokon keresztül már nagyon sok hazánkfia regisztrálta szolgáltatásra. A rejtett karakterfelismerő modult a Dokumentumok főoldalán (docs.google.com) érhetjük el, az esetben, ha feltöltünk a webes tárhelyre egy PDF állományt vagy egy szöveget tartalmazó képet. Ezt már a művelet megkezdése előtt tetten érhetjük, ha rákattintunk a feltöltés ikonjára, majd belelesünk az ott található beállításokba. „A feltöltött fájlok konvertálása a Google Dokumentumok formátumára”, illetve a „Szöveg konvertálása a feltöltött PDF- vagy képfájlokból” lehetőségek igencsak beszédesek. Engedélyezzük azokat, majd próbából töltsünk fel egy beolvasott dokumentumot, arra azonban figyeljünk, hogy a megjelenő panelen jól határozzuk meg annak a nyelvét. Ennyi az egész.
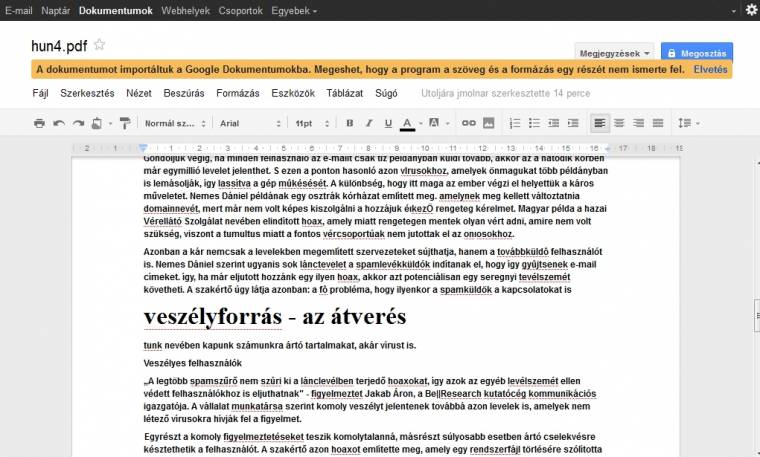
Csodát azonban ne várjunk, mivel tapasztalatunk alapján egyelőre meglehetősen butuska a Google OCR-modulja, legyen szó angol vagy magyar nyelvű dokumentumról. Még a cég anyanyelvén sem működik jól a megoldás, sok esetben az alapvető szavakat is eltéveszti, arról nem is beszélve, hogy a formázásokkal nehezen küzd meg – bár e tekintetben egy fokkal hatékonyabb, mint a szintén ingyenes FreeOCR, amely egyébként a Google által szponzorált OCR-re épül. Faramuci helyzet. Sajnos azt sem tehetjük meg, hogy egymás mellé rendezzük a beolvasott és a konvertált oldalakat, mivel a webszolgáltatás erre még nem képes. Pozitívumként azonban elmondható, hogy magát az átkonvertálást nagyon gyorsan hajtja végre, a Google méretes szerverparkjának köszönhetően. Ha a nagy riválissal kell szembeállítanunk a Google OCR-modulját, akkor azt kell mondanunk, hogy magyar nyelv esetén egy fokkal jobb, mint a OneNote, angol dokumentumoknál ellenben a Microsoftnak áll a zászló.
Fejlesztő: Google
Ár: ingyenes
Web: docs.google.com
Kompatibilitás: Windows, Linux, és Mac OS X
Előny: ingyenes, gyors átkonvertálás
Hátrány: nagyon sok hibával dolgozik
Teljesítmény: 2
Kezelhetőség: 3
Ár/érték: 3
Microsoft OneNote 2010
A Microsoft ügyesen elrejtett egy optikai karakterfelismerőt az irodai programcsomagjában, amely olyan jól sikerült, hogy a felhasználóknak csak egy kis része tud róla, pedig ott van „Microsoft Office Document Imaging” néven. Ha véletlenül nem találnánk, akkor a programok eltávolításánál keressük meg a szoftvercsomagot, kattintsunk a módosításra, majd a telepítendő elemeknél jelöljük ki azt, ha eddig nem engedélyeztük volna. Kizárólag a OneNote jegyzetelőben vehetjük igénybe a szolgálatait, amellyel szinte mindent felismertethetünk, képeket, beszkennelt állományokat és akár PDF dokumentumokat is. Ennek köszönhetően például egy weblap szövegét is gyorsan lementhetjük, ha készítünk róla egy képernyőfotót, a jobb klikkel előcsalható panel legalján engedélyezzük, hogy az objektum kereshető legyen, majd ugyanitt kiadjuk a Szöveg másolása képből utasítást, és beillesztjük azt egy megfelelő helyre. E módszerrel bármit felismertethetünk, legyen szó egy PDF-es fájlnyomatról, vagy egy OneNote-tal beszkennelt dokumentumról.
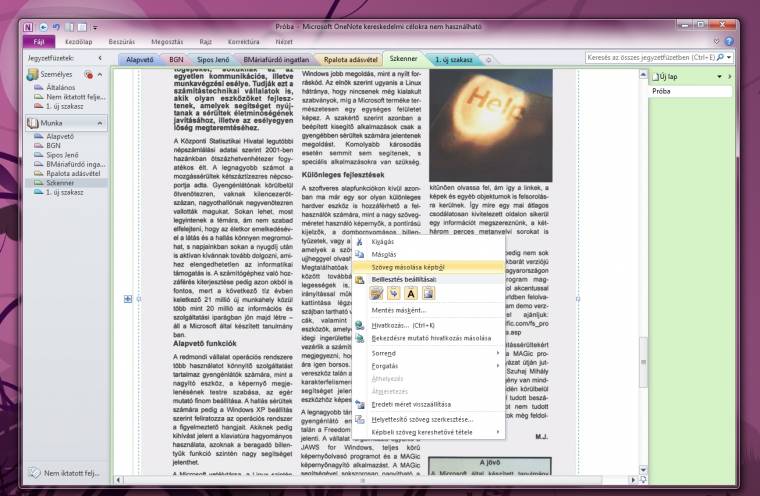
Tapasztalatunk szerint komolyan megszenved a program, ha egy nagyobb dpi-s objektum érkezik hozzá, így vélhetően alapbeállításon 150-es vagy 200-as dpi értékkel dolgozik, pedig szüksége lenne a nagyobb felbontásra, mivel a gyakorlatban meglehetősen rosszul muzsikál a Microsoft OCR-je. Mondjuk azt, hogy félprofi. Még egy A4-es oldalon lévő normál méretű szöveg esetén is elkövet legalább több mint két tucat hibát, és ha magyar szövegről van szó, pláne több hasábba tördelve, akkor már használhatatlan. A webről lementett „az Intel helyet szeretne csinálni a termékpalettáján” szövegből például a következőt hozta ki: „az Intel helyet szeretne csinbi a termkpa1ettjn”. Ez általános, arról nem is beszélve, hogy mivel csak formázatlan szövegként ment, ezért minden fajta formázásnak, így a sortöréseknek is búcsút mondhatunk OneNote mellett, ami hosszabb szövegeknél nagyon kényelmetlen. Annyit tudunk a javára írni, hogy ingyen van, ha már rendelkezünk egy Office csomaggal.
Fejlesztő: Microsoft
Ár: 28 ezer Ft (Office Home & Student)
Web: office.microsoft.com
Kompatibilitás: Windows
Előny: az Office-ban már benne van, mindent gyorsan felismertethetünk
Hátrány: angol nyelvvel is megküzd, nemhogy a magyarral
Teljesítmény: 2,5
Kezelhetőség: 3
Ár/érték: 4
Nuance OmniPage 18
A Finereadernél már utaltunk arra, hogy nem volt teljesen egyértelmű, hogy jelenleg melyik a legjobb optikai karakterfelismerő a piacon; végül az ABBYY megoldása győzött, de csupán egy hajszállal, ugyanis az OmniPage hasonlóan gazdag funkciókészlettel rendelkezik, sőt tesztünk alapján egy fokkal hatékonyabb (bár ez még hibahatáron belül van). Emellett rendelkezik natív SharePoint-, Dropbox- és Evernote-csatlakozóval is, a Cloud Connector moduljával pedig a Google és a Microsoft felhőjébe is tud menteni, amely képességre bizonyára sokan felkapják a fejüket. Miért nyert mégis inkább a Finereader? Két okból. Egyrészt az OmniPage nem rendelkezik magyar felhasználói felülettel, ami Magyarországról nézve egy méretes hiányosság, másrészt – és talán ez a fontosabb – az oldalak elrendezésénél sok esetben gondja akadt az OmniPage-nek.
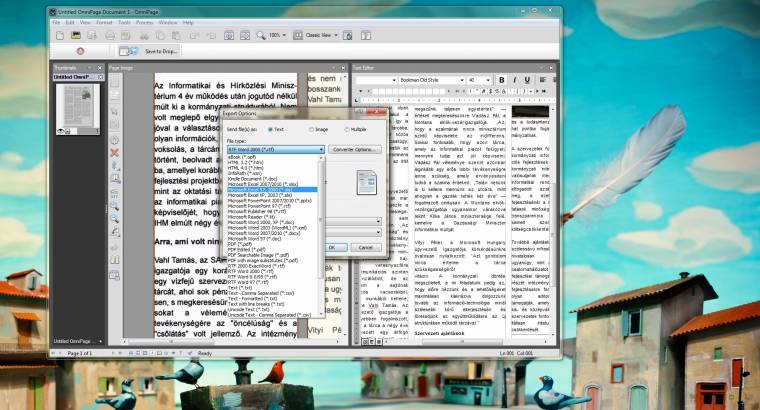
Pozitívum, hogy a program a lehető legjobban igyekezett megtartani az eredeti állapotot, de sok esetben nem igazította ehhez hozzá a szöveget, így az néha hosszabb lett a kelleténél. Persze felhasználói beavatkozással orvosolható a probléma, de tesztünkben azt a szoftvert kerestük, amely a legjobban tudja visszaadni a beolvasott állapotot, a lehető legkevesebb segítség nélkül, és e téren csak a második pozícióban áll az OmniPage. Főként, hogy a „ő” karaktereket ahol lehet, megpróbálja rövidíteni. Ezen túl nem nagyon lehet belekötni az OCR-motorjába. Megbízhatóan teszi a dolgát – magyar nyelvű dokumentumoknál is –, csak nagyon kevés felhasználói segítséget igényel; ha pedig mégis, akkor egy jól használható szövegszerkesztő áll a rendelkezésünkre. Amennyiben készen vagyunk, akkor akár még hátra is dőlhetünk, mivel az OmniPage fel tudja olvasni a felismert szöveget, sőt azt még WAV formátumba is lementhetjük. Sajnos itt szintén nincs magyar nyelvi támogatás, de tehetünk egy próbát a francia búgóhangú Virginnel, az amerikai Tommal vagy éppen a svéd Ingriddel, hogy az ő szájukból miként hangzanak a fülünknek ismerős mondatok. Erre akár egy munkafolyamatot is beállíthatunk, hogy a program az éjszaka közepén a céges dokumentumainkat Ingrid hangján a Dropbox-fiókunkba küldje.
Fejlesztő: Nuance
Ár: körülbelül 34 ezer Ft (Standard)
Web: nuance.com
Kompatibilitás: Windows
Előny: gazdag funkcionalitás, Dropbox- és Evernote-támogatás
Hátrány: nincs magyar nyelvű felület
Teljesítmény: 4
Kezelhetőség: 5
Ár/érték: 4,5
